

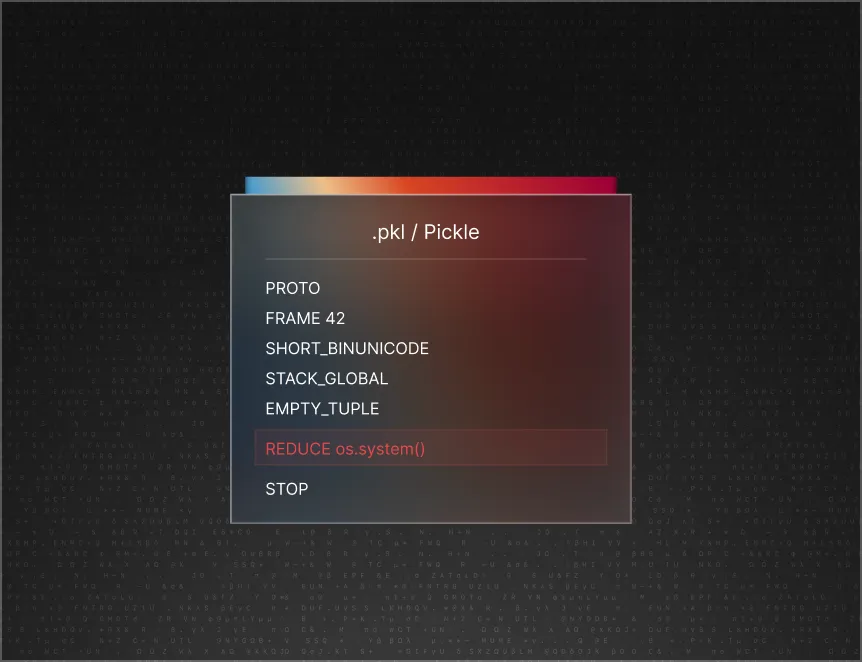
AI model files are an unscanned attack surface
Models from HuggingFace, Kaggle, and GitHub are deployed into production without security review. Traditional AppSec tools—SAST, DAST, SCA—don’t understand model formats or their attack surfaces. A single .pkl file can execute arbitrary commands when loaded.
Arbitrary code execution
Pickle-based models can run system commands on load. One malicious model file means full system compromise.
.webp)
Embedded secrets
Cloud keys, API tokens, and credentials stored in model metadata leak into production environments undetected.
.webp)
Model poisoning & backdoors
Manipulated outputs triggered by specific inputs. LoRA adapters with spectral anomalies suggesting targeted poisoning.
.webp)
Supply-chain tampering
Modified models served from trusted-looking sources. Hash mismatches between hosted metadata and downloaded artifacts.
.webp)




Format-level static analysis, no execution required
AMSP parses raw bytes and internal structures of model files to detect threats at the format level. No model execution, no GPU, no dependency on ML frameworks. Think SonarQube for AI models.
Everything you need to secure your model supply chain
Dedicated scanners for every major model format:
Pickle-based
(.pkl, .pt, .pth, .ckpt, .bin, .joblib): Opcode-level analysis. Detects dangerous imports and code execution patterns like os.system, subprocess, eval.
SafeTensors
(.safetensors): Header and tensor validation. Detects oversized headers, invalid JSON, unknown dtypes, corruption.
GGUF
Magic byte and metadata inspection. Detects malformed metadata and suspicious embedded strings.
ONNX
(.onnx): Graph traversal and operator inspection. Detects external data references and suspicious operators.
Keras/H5
(.h5): Static structure inspection. Detects lambda deserialization risk and custom object injection.
NumPy
(.npy, .npz): Header and dtype validation. Detects object dtype injection risk and pickled payloads.
LoRA adapters
Spectral and SVD anomaly analysis. Detects spectral dominance, entropy anomalies, rank collapse, norm outliers.
Embedded secrets detection
Detects common secret patterns across all supported formats:
Cloud credentials (AWS, GCP, Azure)
LLM provider keys (OpenAI, Anthropic, and others)
GitHub and Slack tokens, JWTs
Private endpoints and internal URLs
Includes evidence location and remediation guidance: remove, rotate, re-export.
.webp)
Supply-chain integrity & provenance validation
Hash and integrity validation when metadata is available
Version-to-version tampering signals
Provenance context with source and production signals
Optional HuggingFace verification workflows via hf:// reference

Risk scoring (0–100) with explainability
Each scan produces a risk score for CI gating and policy enforcement. Severity + confidence-based scoring with category weighting (RCE weighted higher than structural anomalies). Every finding includes a “why flagged” explanation with evidence references.
.webp)
CI/CD & MLOps integration
Designed for shift-left and continuous validation
CLI for local scanning
CI gating: fail builds on severity thresholds
SARIF output for code scanning platforms
Pre-commit hook support
Containerized deployment for internal environments
.webp)
Compliance-ready reporting
SARIF 2.1.0 output
CycloneDX-style exports (ML-BOM style reporting)
JSON manifests for dashboards and integrations
.webp)
Why AMSP

No execution required
Pure static analysis at the byte and structure level. No GPU, no ML framework dependencies, no risk of triggering malicious payloads during scanning.
Format-native depth
Not a generic file scanner. Dedicated parsers for Pickle, SafeTensors, GGUF, ONNX, Keras, NumPy, LoRA, and TorchScript—each with format-specific threat detection.
Pipeline-native
CLI, CI gating, SARIF, pre-commit hooks, and Docker deployment. Fits into existing AppSec and MLOps workflows without a separate tool chain.
Who is it for ?
ML Platform / MLOps teams
Gate model promotion and deployment with automated security scanning.
AppSec teams
Enforce policy on model artifacts and generate consistent evidence.
Security leadership
Visibility, risk scoring, and audit-ready reporting across model supply chains.
DevOps teams
Automate scanning across pipelines and registries.
What teams achieve
- Prevent RCE from unsafe model formats before models are loaded
- Detect and remove embedded secrets before publish or deploy
- Reduce likelihood of backdoored or poisoned artifacts entering production
- Enforce policy controls on model artifacts comparable to code security controls
- Produce audit-ready evidence for AI supply-chain security
- Standardize model security checks across teams and pipelines

